
Cloudera veut pousser Spark plus près d’Hadoop en remplacement de MapReduce. Avec le rachat d’Onyara, Hortonworks veut unifier la plate-forme Hadoop.
Dans l’univers Hadoop, Hortonworks, Cloudera et MapR sont les trois étoiles les plus brillantes avec des positionnements différents : pure open source pour le premier, simplicité pour le second et performance pour le dernier.
Cloudera vient de lancer une initiative pour unifier Spark et Hadoop et créer ainsi une nouvelle génération d’applications analytiques. Depuis longtemps déjà, Spark est le projet plus dynamique de l’écosystème Hadoop et Cloudera a souhaité participé activement à son développement. La firme basée Burlingame, tout près de l’aéroport de San Francisco, fait état de plus de 200 entreprises utilisant Spark – dont notamment Avvo, Barclays, Concur, DigitalGlobe, RelayHealth et Santander UK. Elle affirme avoir cinq fois plus de ressources dédiées à l’ingénierie que tout autre éditeur Hadoop, et avoir largement contribué au développement de Spark en fournissant plus de 370 patches et 43 000 lignes de code.
Issu du laboratoire AMPLab de l’université de Berkeley tout comme le contrôleur de cluster Mesos, Spark est un framework distribué qui permet de faire des traitements de données in-memory sur un cluster de mémoire. Il fait partie de ce que certains appelle le big data de deuxième génération (Second-Generation Big Data Systems) « Spark devient rapidement le complément le plus populaire d’Hadoop, à mesure que les entreprises cherchent un moteur d’exécution facile à utiliser, rapide et polyvalent pour répondre à leurs besoins analytiques – streaming, traitements orientés graphe et même machine learning » considère Nik Rouda, Senior Analyst du cabinet de conseil ESG. Et « Spark est bien parti pour prendre la succession de MapReduce, poursuit Mike Olson, Fondateur et Chief Strategy Officer chez Cloudera. S’il permet d’exécuter des centaines de jobs simultanément et fonctionne sur des clusters multi-tenant dotés de dizaines de milliers de nœuds, il reste quelques ajustements à apporter ». C’est donc l’objectif que vise Cloudera avec la communauté des développeurs.
Un des avantages de Spark est qui peut s’interfacer avec de nombreux systèmes de fichiers, notamment HDFS, HBase (inspiré de BigTable de Google), Cassandra NoSQL issu de Facebook, S3 d’AWS. Les données qui ne peuvent être placé In-memory sont poussées sur les disques du cluster. Spark offre donc des niveaux de performances nettement supérieures à MapReduce estimé à 10 fois lorsque les données sont stockées sur les disques et 100 fois lorsqu’elles sont contenues en mémoire. Spark possède également une couche SQL baptisé Spark SQL qui permet de lancer des requêtes de style SQL sur les données ainsi que Spark Spreaming pour effectuer des traitement analytics sur des flux de données en temps réel. Spark possède également une API permettant d’interfacer le framework avec de très nombreux langages de programmation : Python, Scala, Java, R…
Pour remplacer MapReduce, Spark devra s’adapter au volume des travaux MapReduce en exploitation aujourd’hui qui impliquent souvent des Po de données à travers des milliers de nœuds, voire le dépasser. Spark doit pouvoir soutenoir la charge, améliorer sa stabilité tant sur site que sur le cloud, explique Mike Olson à The Platform (Spark Makes Hadoop Mainstream, Cloudera Jumps In). Yahoo, Baidu, Tencent indiquent avoir mis en place de telles configurations et Databricks, la société propose une version commerciale de la pile Spark en version stand alone, affirme qu’un de ses clients utilise une application qui ingère de Po de données sur un cluster de plus de 8000 nœuds. La « scalabilité » est donc une des dimensions que devrons améliorer tous les protagonistes impliqués dans le développement de Spark.
Faciliter l’administration de Spark est également un élément important pour accroître son adoption. Cloudera a de son côté travaillé à l’intégration de Spark avec Hadoop YARN pour la gestion des ressources partagées, en le connectant avec d’autres environnements Hadoop comme Impala et Apache Solr, et en ajoutant des indicateurs utiles pour les diagnostics.
L’initiative « One Platform » vise à faciliter l’administration de Spark à travers des configurations automatiques ; l’amélioration du caractère multi-tenant, des performances et de la facilité d’utilisation de Spark-on-YARN ; une visibilité accrue sur l’utilisation des ressources ; et un processus d’installation enrichi de PySpark pour un accès via Python.
Cloudera n’est pas la seule entreprise à pousser Spark, MapR Technologies, Hortonworks et même IBM y travaillent activement. IBM vient de dévoiler une nouvelle version de sa solution BigInsights V4 distribution et consacre 3500 chercheurs et développeurs au big data. MapR a annoncé récemment trois solutions Spark ( Real-time Security Log Analytics, Time Series Analytics, Genome Sequencing) permettant un démarrage rapide.
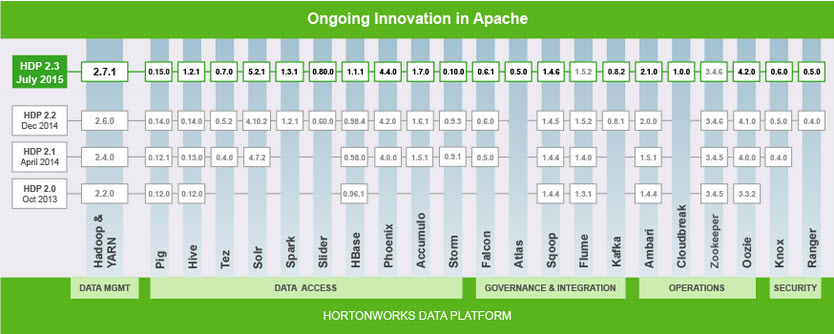
Hortonworks a introduit en juin dernier HDP 2.3 qui intègre la version 1.3.1 de Spark. La firme basée à Santa Clara s’est récemment distingué en rachetant Hortonworks vient d’annoncer l’acquisition d’Onyara, un des principaux contributeurs au projet open source Apache NiFi. Cette acquisition vise à assurer à automatiser et sécuriser les flux de données ainsi que d’assurer la collecte et le traitement des informations en temps réel à partir d’innombrables données et de les exploiter efficacement.
L’Internet des Objets fait exploser le volume des données en incluant les données issues des machines, capteurs, appareils de géolocalisation, médias sociaux, parcours sur la toile, registres des serveurs. On parle désormais de l’Internet of Anything (IoAT), autrement dit Internet de tous les objets,. De nombreuses applications IoAT exigent des connexions bilatérales et une sécurité optimale de la périphérie jusqu’au centre de données. La faille qui en résulte renforce la nécessité de mettre en œuvre des fonctions de sécurité, de protection des données, de gouvernance et de gestion des sources. Ces applications doivent pouvoir accéder aussi bien à des données mobiles qu’à des données fixes.
Tandis que la majorité des solutions actuelles sont des solutions sur mesure, peu sécurisées, non intégrées et dont la gestion est complexe, la solution Hortonworks DataFlow basée sur Apache NiFi est censée simplifier et accélérer le flux de données en mouvement dans HDP pour une analyse des plus fiables. Combinées à HDP, ces offres complémentaires mettront à disposition des utilisateurs un ensemble complet de solutions sécurisées pour traiter et tirer parti du volume croissant des données de l’IoAT.
Apache NiFi est disponible depuis l’automne 2014 dans le cadre du programme NSA Technology Transfer. Au cours de ces huit dernières années, les ingénieurs d’Onyara ont participé au projet logiciel du gouvernement américain qui a donné naissance à Apache NiFi. En juillet 2015, NiFi est devenu un projet de grande envergure avec l’intégration de sa communauté et de sa technologie à la Fondation Apache.

 puis
puis