
Alors que le marché des bases de données s’est stabilisé autour du trio Oracle/IBM/Microsoft et plus récemment SAP, les bases de données open source ont gagné en maturité et deviennent un choix réaliste.
Tel est le message d’une note publiée par le Gartner (The State of Open Source RDBMS) qui milite pour une nouvelle réflexion sur l’opportunité de choisir une solution open source pour remplacer l’existant. L’argumentaire du cabinet de conseil est simple. Les bases de données open source sont devenues et le différentiel fonctionnel avec les ténors du marché se sont réduits significativement. Elles apportent le même niveau en termes de haute-disponibilité, de scalabilité et de clustering.
Ces bases de données open source se sont largement enrichies d’outils tiers, proposés non seulement par les fournisseurs de ces bases de données mais aussi par des acteurs traditionnels comme Dell (anciennement Quest Software) et Embardero. Et donc à périmètre fonctionnel et performance proches, les bases de données open source sont source d’économies plus que substantielles.
Parmi les acteurs de ce marché, on peut citer PostgreSQL, Ingres et MySQL. Suite à la reprise de MySQL par Oracle, Maria DB, un fork de MySQL proposé par Maria DB et VoltDB, un SGBD open source in-memory sont apparus. Les SGBD open source sont utilisés à la fois en mode transactionnel, data warehouse et analytics.
Pour le Gartner, il ne s’agit pas de passer d’un coût vers les SGBD Open source mais plutôt de le faire progressivement et avec discernement. D’abord en choisissant des applications qui ne sont pas stratégiques pour l’activité de l’entreprise. Ensuite, évoluer en sélectionnant les applications les mieux adaptées à une telle migration.
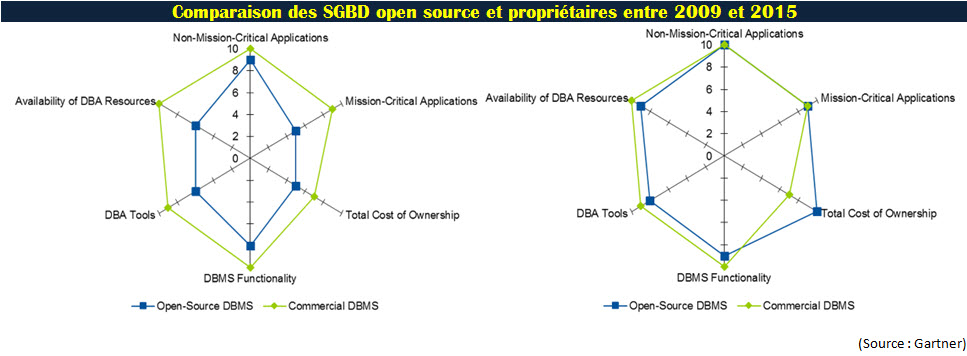
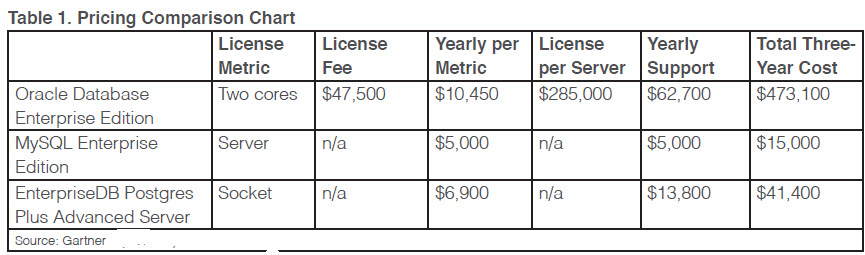
Sur six critères d’évaluation (voir schéma ci-dessus), les SGBD open source se sont largement rapprochés de leurs concurrents propriétaires en offrant un avantage très important concernant les coûts et plus spécialement le TCO (le coût total d’utilisation ou Total Cost of Ownership). Et sur ce point, la comparaison est criante. Une évaluation sur trois de ce fameux TCO porte à plus de 470 000 dollars le coût d’une base Oracle Contre 41 000 pour la version Postgres Plus d’enterpriseDB et 15 000 dollars pour la version Enterprise de MySQL.
Maria DB, PostgreSQL et MySQL : trois SGBD Open Source
Maria DB version printemps 2016 renforce les fonctionnalités OLTP

The MariaDB Seal Logo
MariaDB Corporation a présenté en mars la version Printemps 2016 de MariaDB Enterprise. De nouvelles fonctionnalités protègent les données contre les attaques menées via les applications et le réseau et accélèrent le développement d’applications. MariaDB lance également le service d’audit de la sécurité MariaDB (MariaDB Security Audit) pour que les entreprises puissent identifier et remédier les défaillances qui menacent la sécurité des données.
Cette version Printemps garantit la sécurité à tous les niveaux de la base de données. Elle protège contre les attaques par injection de code SQL et par déni de service et chiffre de manière transparente les données qui sont au repos dans la base de données ou qui transitent depuis et vers les applications. Les entreprises peuvent réduire le risque de violation de données en stockant les clés de chiffrement dans le système de gestion des clés indépendant de leur choix dont Eperi et AWS . Elles peuvent également profiter d’une authentification Kerberos, de plug-ins de validation des mots de passe et d’un contrôle d’accès à base de profil.
Disponible sur abonnement, MariaDB Enterprise comprend la toute dernière version de MariaDB server 10.1.12, des connecteurs LGPL, MariaDB MaxScale 1.4, des ressources de développement et des outils de productivité pour les administrateurs DBA, des plug-ins pour la gestion des bases de données ainsi qu’un support expert 24/7 et des services afin de répondre aux exigences des applications critiques.
PostgreSQL 9.5: evolution vers le big data
 Le PostgreSQL Global Development Group a présenté en février PostgreSQL 9.5. Cette nouvelle version intègre des fonctionnalités, notamment la fonctionnalité UPSERT, les politiques de Row Level Security, ainsi que de multiples fonctionnalités autour des bases Big Data.
Le PostgreSQL Global Development Group a présenté en février PostgreSQL 9.5. Cette nouvelle version intègre des fonctionnalités, notamment la fonctionnalité UPSERT, les politiques de Row Level Security, ainsi que de multiples fonctionnalités autour des bases Big Data.
UPSERT
Demandée depuis plusieurs années par les développeurs, la fonction « UPSERT » est un diminutif de la commande « INSERT, ON CONFLICT UPDATE », qui permet de traiter de manière identique les nouvelles lignes et celles qui sont mises à jour. UPSERT simplifie le développement d’applications web et mobile en déléguant à la base de données la gestion des éventuels conflits lors de modifications concurrentes. Cette fonction facilitera la migration des anciennes applications MySQL vers PostgreSQL.
Développée pendant 2 ans par Peter Geoghegan de la société Heroku, l’implémentation d’UPSERT dans PostgreSQL est plus flexible et plus puissante qu’avec les autres bases de données relationnelles.
La nouvelle clause ON CONFLICT permet d’ignorer certaines données ou de mettre à jour d’autres colonnes ou d’autres tables, de manière à supporter les traitements complexes lors de chargement de données avec un ETL. Comme toujours avec PostgreSQL, tout cela fonctionne parfaitement dans un environnement multi-transactionnel et s’intègre directement avec les autres fonctionnalités, notamment la réplication logique.
Row Level Security
Avec la fonctionnalité nommée « Row Level Security » (RLS), PostgreSQLpropose une gestion de droits par ligne et par colonne capable de s’intégrer dans un système de sécurisation avancé comme SE Linux. RLS renforce sa position de favori pour les applications critiques notamment celles qui nécessitent de respecter les standards PCI, HIPAA et la directive européenne de protection des données.
RLS est l’aboutissement de 5 ans d’efforts dans le domaine de la sécurité, avec notamment les contributions de KaiGai Kohei de la société NEC, Stephen Frost de la société Crunchy Data et Dean Rasheed. Désormais, les administrateurs de bases de données peuvent définir des règles de sécurité en filtrant les lignes d’une table selon les droits d’accès de l’utilisateur. Cette méthode de sécurisation des données permet de résister aux attaques par injection SQL et aux failles de sécurité au niveau applicatif.
Big Data
PostgreSQL 9.5 intègre des avancées pour les grands volumes de données. Ces avancées sont le signe que PostgreSQL continue d’avoir un rôle important parmi les solutions Big Data open source. Dans les fonctionnalités proposées on retrouve notamment :
– Les index BRIN: une nouvelle méthode pour créer des index très légers mais très efficaces sur les tables volumineuses et « naturellement ordonnées ».
– Des tris encore plus rapides: désormais PostgreSQL peut trier les données textuelles et NUMERIC plus rapidement, grâce à un algorithme appelé « abbreviated keys ».
– CUBE, ROLLUP et GROUPING SETS: 3 nouvelles clauses issues du standard SQL qui permettent aux utilisateurs de créer des rapports avec plusieurs niveaux d’agrégation de données en utilisant une seule requête SQL.
– Les Foreign Data Wrappers (FDWs): Déjà présents dans les versions précédentes, ils permettent d’utiliser PostgreSQL comme un moteur de recherche pour des systèmes Big Data comme Hadoop et Cassandra.
MySQL 5.7 : amélioration des performances
 En octobre 2015, Oracle annonçait MySQL 5.7, une nouvelle version qui améliore significativement les performances. Elle intègre des fonctions NoSQL enrichies avec le support de JSON et MySQL Router qui facilite la connexion des applications à plusieurs bases de données MySQL.
En octobre 2015, Oracle annonçait MySQL 5.7, une nouvelle version qui améliore significativement les performances. Elle intègre des fonctions NoSQL enrichies avec le support de JSON et MySQL Router qui facilite la connexion des applications à plusieurs bases de données MySQL.
– Principales évolutions de MySQL 5.7 améliorant les performances :
- Vitesse améliorée : Dans des tests comparatifs utilisant des opérations en lecture seule de type SysBench Point-Selects, avec 1 024 connexions, MySQL 5.7 a pu traiter 1 600 000 requêtes par seconde (QPS) – soit 3 fois plus que MySQL 5.6.
- InnoDB optimisé : Les nouveautés améliorent notamment les performances et la concurrence, les opérations en ligne, les index spatiaux ou encore le partitionnement natif.
- Réplication plus robuste : Les améliorations des fonctions de réplication de MySQL intègrent notamment la réplication multi-sources, des identifiants globaux de transaction (GTID) renforcés, et des serveurs esclaves multi-threadés améliorés assurant une scalabilité et une disponibilité accrues.
- Optimiseur enrichi : Le nouveau modèle de coût dynamique de l’optimiseur MySQL améliore la performance des requêtes et peut être mieux contrôlé par l’utilisateur.
– Principales évolutions de MySQL 5.7 concernant l’administration :
- Nouveau type de données natif JSON et nouvelles fonctions JSON : pour stocker, rechercher et manipuler des données sans schéma de façon efficace et souple, avec notamment un nouveau format binaire interne, une intégration plus facile dans SQL et la gestion des index sur les Documents JSON en utilisant les colonnes générées.
- Performance Schema : il permet une instrumentation de la mémoire, des transactions, des routines stockées, des instructions préparées, de la réplication et des verrous.
- MySQL SYS Schema : il fournit des objets utilitaires pour répondre facilement aux questions que l’on se pose habituellement en matière de performance, d’état du système, d’usage et de surveillance.
- Sécurité renforcée : pour faciliter et sécuriser encore plus l’initialisation, la configuration et la gestion d’une instance MySQL
- Support étendu des systèmes d’information géographiques (SIG) pour les applications mobiles : il intègre le support des index spatiaux dans InnoDB, GeoJSON et GeoHash.

 puis
puis